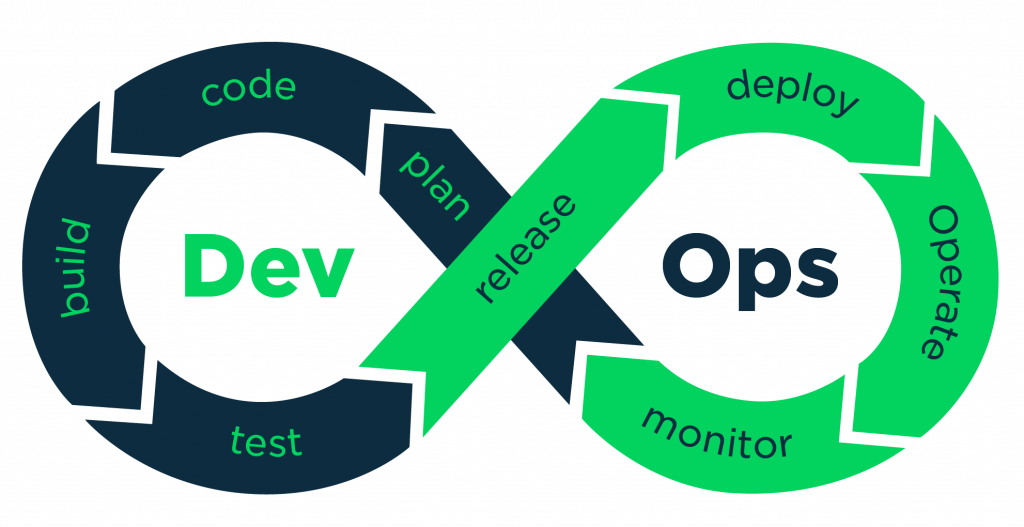
A case in point is our attempt to put in place Blameless Post-Mortems. A blameless postmortem (or retrospective) is a post-incident document that helps teams figure out why an incident happened, and brainstorm how to improve the process to prevent similar incidents from happening again. It’s easy to conceptualize but human conditioning over many years makes it difficult to pull off. The mindset of assigning blame for human mistakes is still embedded into the organisational psyche. It’s tough to balance accountability and growth or learning but it is something that we need to learn to strike.
Another challenge is monitoring. The organisation is steeped in very traditional monitoring approaches with little scope for engineering. Engineers are handling issues that they know are a more immediate need and those that are already hurting the organisation. It takes time to move engineers conditioned for firefighting to work on fire prediction.
I also did not anticipate the dearth of talent available in this area. We need people who understand Network Automation and have an affinity for programming. In my experience, it’s quite tough to look for these attributes in Asia but my counterparts in US and UK found it less of an issue to fill up these required roles. I am looking to expand our technical capabilities in the Asia-Pacific region to catalyse the transformation. It’s challenging but we are getting there, albeit slower than what I would have preferred. My immediate task now is to keep the troops focused on what we are doing and planning to achieve with NRE.
Transforming the existing workforce into the NRE ways of working initially faced a roadblock due to the team’s lack of exposure to “novel” practices. This led to initial scepticism and a lack of faith in the path forward. Getting them all on the same page with learning and understanding the common practices and terminologies used helps to grease things quite a bit. We are planning investments in this area.